

What is Supervised Learning?
Supervised learning is a predictive modelling technique, characterized by the making of an algorithm which learns to map an input to a particular output. This is achieved by training the model on a labeled dataset, which includes a set of input variables and their corresponding output variables. The training process is repeated until a satisfying performance is achieved. During each iteration, the machine creates a set of rules between the input and the output data. This process allows the model to learn from the dataset and apply the rules to accurately predict the output when a new input data is given.
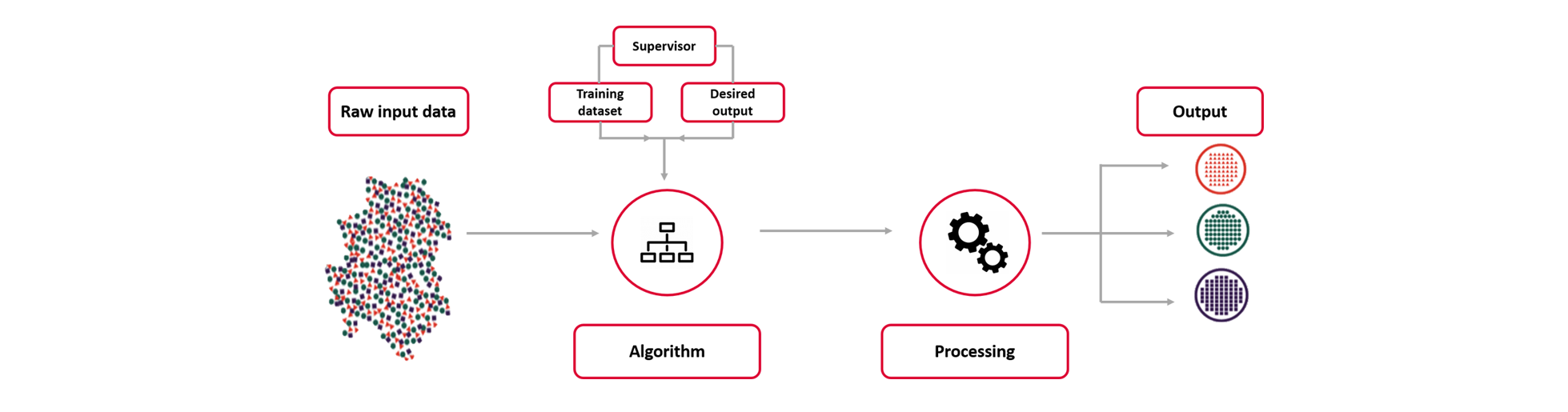
Supervised learning can be classified into two techniques: classification and regression.
Below, we will be focusing on the latter. For more information on regression models, classification and Linedata’s use of these techniques, keep an eye out for upcoming articles.
Regression
Unlike classification which predicts categories or labelling, regression models predict a continuous-valued output based on an independent input variable. This technique is used whenever the required output prediction is a continuous numerical variable, such as for Weather forecasting or Market trends. Different regression models exist and differ based on the relationship between the dependent and independent variables considered, as well as the number of independent variables being used in the model. Some of the main regression algorithms include simple and multiple linear regression, Poisson regression and Support Vector Regression (SVR).
Hence, regression analysis is a form of inferential statistics, used to find trends in our data. There exist multiple different regression algorithms with the common goal of determining a continuous-valued output based on an independent input variable.
A use case of supervised machine learning

For more details, please see: “Bank of America brings AI to equity capital markets”
Hopefully this article will have given you background information on Supervised Machine Learning and it’s branch of regression models. In the following articles, we will dive into the main algorithms used in supervised regression learning and an example of a use case at Linedata.