In the more recent years, Linedata implemented machine learning algorithms in front-office products as well as in back-office solutions. In previous articles, we dove into supervised machine learning as well as the various algorithms that can be used as regression models. In this article, we will be looking at trade error prediction, one of the company’s uses of supervised regression learning.
Linedata’s use of supervised regression machine learning
At Linedata, we are using various machine learning methods that we implement into our products. One of our most important uses of a supervised regression algorithm is in our trade error prediction.
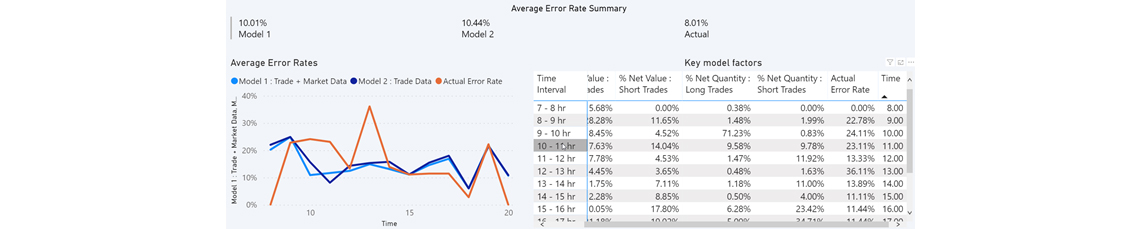
When undertaking post-trade analysis within a system, there is often data available which provides the full trade lifecycle. Using this data, we can look back at the historical trades that have entered the system and determine those that have been amended (manually) or not. Examples of amendments include: changes in quantities and prices, change of fund for which the trade was booked. These modifications may be due to operational or human errors, such as the price having to be changed manually due to a price feed being incorrect or human error at trade initiation. In addition, using the time of the initial trade, it is possible to look at how many trades on average were amended during hourly intervals or what is known as the “error rate”. To do so, we bucket the dataset into hourly periods, which then provides observations of the “error rate” and the trading activity during that hourly period.
Based on these elements, we have built a supervised regression problem to predict the error rate i.e. our predicted variable. The features would be: the aggregated hourly quantity, proportion of quantity/value in that hour in comparison to the whole day, as well as error rates from the previous days. This is a time series approach which looks into the entire data for 10 years and lags each hour of the day to provide additional features such as how the trading data from previous days can influence an upcoming day.
To build this model in Python, we have used the extra-trees from the sklearn library. The extra-trees regressor is based on regression decision trees. Indeed, it implements a meta estimator that fits a number of randomized decision trees, also know as extra-trees, on different samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting.
To learn more about decision trees, please view the upcoming article on the main Supervised Classification Machine Learning algorithms.
What’s next
Hopefully, the previous articles will have given you an idea of one of Linedata’s uses of supervised regression learning.
If you wish to learn more about classification, the second technique for supervised learning, and Linedata’s use of this method, please view the following articles.