Supervised classification learning is at the heart of some of Linedata’s main products. As was depicted in previous articles, supervised machine learning allows to predict an output linked to a particular given input. To do so, the algorithm will learn from the labeled or training data set and will then apply the acquired rules and generalizations to the testing data.
A classification problem requires the output prediction to be to be a discrete class or category, whereas for regression this output will take continuous values. In addition, various classification and regression algorithms can be applied depending on the problem at hand. To learn more about the various algorithms, please view the previous articles published on Linedata’s website.
Below, we will be looking at the trade error scoring, one of the company’s application of supervised classification learning.
Trade error scoring: a use case of supervised classification machine learning
At Linedata, we use various machine learning methods to enhance the efficacy and the workings of our products. One important application is in trade error scoring.
Indeed, to improve our understanding of the market, it is often very useful to look at post-trade analysis of a system. When doing so, we encounter a significant amount of data, which provides the full trade lifecycle. Using this data, we can look at previous trades that have entered the system and determine those that have been modified (manually) and those which have not. These amendments can be the result human or operational errors.
Using this historical trade data, it can be interesting to predict whether a future trade will be amended or not. Indeed, we can calculate the probability, or “error score”, of an incoming trade, which would correspond to the likelihood of this trade being amended or not amended, during the trade lifecycle.
To do so, we use a supervised classification learning method, based on N samples, which correspond to N trades that have occurred in the past. In order to train the model, we have randomly split the data into a training and a test dataset, each containing samples for the input features X and the output class y.
For this problem, features of the input X are initially built from pure trade elements, such as the transaction type or the trade currency. The input features are then enhanced to include a combination of trade and market activity, which are obtained by combining the trade data with market indicators (such as volatility), which are then attached to each trade.
Regarding the output category, we are faced with a binary prediction, as the output will be one of two categories: “an amendment” or “not an amendment”.
Hence the algorithm will generalize and establish rules based on the training data. It will then be able to predict the output category of an incoming trade, based on the input features provided for this trade. Additionally, an error score or probability is established for each trade.
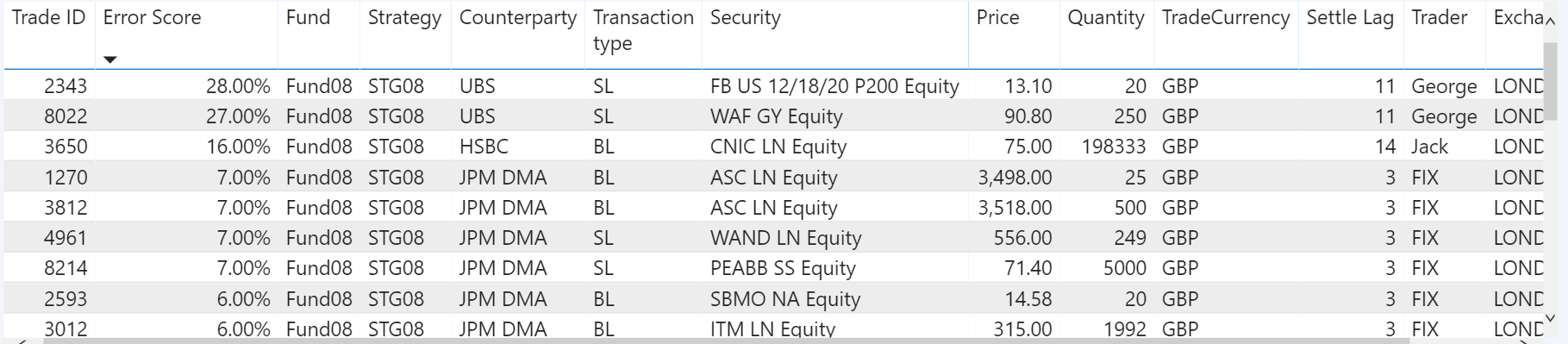
The output of this model is presented in a tabular format, as presented below:
To build this model, we have used the sklearn library in Python, which allows to separate the sample data into a training and a test set, with a default cut-out of 75% training to 25% testing data. From that same library, the extra-trees classifier demonstrated good results for this model. This class implements a meta estimator, which fits a certain number of randomized decision trees on various samples from the dataset. It then uses averaging to improve the predictive accuracy and control over-fitting. Below are the inputs that can be given to this classifier:
To learn more about decision trees and randomized forests, please view the previous articles on the main classification algorithms.
What’s next
Hopefully this article, along with the previous ones, will have given you a good understanding of supervised classification learning and the use of this machine learning technique at Linedata. Keep an eye out for future articles!